
انتخاب ویژگی با روش های فیلتر (فیلتر F-score)
انتخاب ویژگی با روش های فیلتر یا روش های انتخاب ویژگی مبتنی بر فیلتر ، در این پروژه در یک مرحله با استفاده از روش فیلتر F-score انتخاب ویژگی انجام می شود. سپس با طبقه بند SVM ، طبقه بندی انجام می شود.
انتخاب ویژگی با روش فیلتر F-score و طبقه بندی با طبقه بند SVM
هدف این پروژه بررسی تاثیر انتخاب ویژگی به روش فیلتر و بر اساس وزن دهی به ویژگیها روی دقت طبقه بند بوده است. در این پروژه در گام اول انتخاب ویژگی صورت گرفته است و در گام دوم مدل طبقه بند ساخته شده است. برای محاسبه فیلتر f-score یا وزن ویژگیها از معیار اطلاعات متقابل که روشی قوی می باشد استفاده کرده ایم.
فیلتر F-score
معیار اطلاعات متقابل
شرایط رتبهبندی تئوری اطلاعات، وابستگی بین دو ویژگی را به کار میگیرد، برای اینکه اطلاعات متقابل (MI) ، توضیح داده شود ابتدا تعریف آنتروپی بیان میگردد:
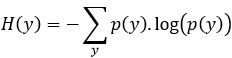
این رابطه عدم قطعیت در خروجی را نمایش میدهد. حال فرض شود متغیر X نیز مشاهده شده است ، آنگاه آنتروپی شرطی برابر است با:

رابطهی بالا نشان میدهد ، که با مشاهده متغیر X ، عدم اطمینان خروجی y کاهش مییابد و مقدار عدم قطعیت به صورت رابطهی … نمایش داده شده است:

که این رابطه ، MI بین y و X را نشان میدهد و این بدان معنی است که اگر X و y مستقل باشند آنگاه MI صفر خواهد بود ، و اگر بهم وابسته باشنه MI بزرگتر از صفر خواهد بود و هر چی مقدار وابستگی بیشتر باشد ، آنگاه مقدار MI بیشتر خواهد بود.
طبقه بند SVM
ماشین بردار پشتیبان یا SVM در واقع یک طبقهبندی کننده دودویی است که دو کلاس را با استفاده از یک مرز خطی از هم جدا میکند. در این روش با استفاده از تمامی باندها و یک الگوریتم بهینه سازی ، نمونههایی که مرزهای کلاسها را تشکیل میدهند به دست میآورند. این نمونه ها را بردارهای پشتیبان گویند. تعدادی از نقاط آموزشی که کمترین فاصله تا مرز تصمیم گیری را دارند میتوانند به عنوان زیر مجموعه های برای تعریف مرزهای تصمیم گیری و به عنوان بردار پشتیبان در نظر گرفته شون
فرض کنید مجموعه نقاط داده زیر را در اختیار داریم و میخواهیم آنها را به دو طبقه Ci = {-1,1} تفکیک کنیم.هر Xi یک بردار p بعدی از اعداد حقیقی می باشد که در واقع همان ویژگیهای استخراج شده از تصاویر میباشد.

روشهای طبقه بندی خطی، سعی دارند که با ساختن یک ابرسطح ( که عبارت است از یک معادله خطی) ، دادهها را از هم تفکیک کنند. روش طبقه بندی ماشین بردار پشتیبان که یکی از روشهای طبقهبندی خطی است، بهترین ابرسطحی را پیدا میکند که با حداکثر فاصله (maximum margin) ، دادههای مربوط به دو طبقه را از هم تفکیک کند.
داده های مورد استفاده
در این پروژه از داده های Arcene استفاده شده است
لینک داده ها
https://archive.ics.uci.edu/ml/datasets/Arcene
نتایج به دست آمده
در این قسمت نتایج کار با و بدون ویژگی آورده شده است. لازم به ذکر است برای انتخاب ویژگی ، ویژگیهایی که معیار آنها بالاتر از ۰٫۷ بودند انتخاب شدند. معیار ذکر شده بر حسب درصد است.
| با انتخاب ویژگی | بدون انتخاب ویژگی | |
| ۱۰۰ | ۱۰۰ | آموزش |
| ۸۴ | ۸۲ | آزمون |
بر اساس جدول بالا میتوان گفت انتخاب ویژگی کارایی svm را بهبود داده است. در حالتی که ویژگی با وزن بالاتر از ۰٫۷ انتخاب گردند، آنگاه تعداد ویژگیهای انتخابی برابر ۱۵۹۷ شده است.
کارشناسان وب سایت MATLABDL قادر به انجام پروژه در زمینه های مشابه نیز می باشند.
قیمت پروژه : ۶۰۰۰۰ تومان
حجم : ۱٫۹۵ مگابایت
توضیحات : پیاده سازی در نرم افزار متلب انجام شده است.
کلمات کلیدی: انتخاب ویژگی با روش های فیلتر,فیلتر F-score,طبقه بند SVM,داده های Arcene,
منبع : مطلب دی ال
رمز فایل : www.matlabdl.com



دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.