طبقه بندی مجموعه داده IRIS با الگوریتم طبقه بندی KNN در نرم افزار متلب
طبقه بندی مجموعه داده IRIS با الگوریتم طبقه بندی KNN در نرم افزار متلب عنوان پروژه ای است که توسط کارشناسان وب سایت مطلب دی ال آماده شده است ، در ادامه توضیحاتی در مورد این پروژه آورده شده است و در انتها هم لینک دانلود پروژه را قرار داده ایم.
طبقه بندی مجموعه داده IRIS با الگوریتم طبقه بندی KNN در نرم افزار متلب
چکیده طبقه بندی دیتاست IRIS با الگوریتم KNN در نرم افزار متلب:
امروزه سیستم های تصمیم گیر خودکار در بسیاری از زمینه ها کاربرد دارند. یکی از روش های تصمیم گیری خودکار استفاده از داده های قبلی است. با این روش می توان از داده هایی که قبلا مشاهده شدند در مورد داده های جدید تصمیم گیری نمود. با استفاده از طبقه بندها که ابزار قدرتمندی برای تصمیم گیری هستند، در مورد نمونه های جدید تصمیم گیری کرد. یکی از طبقه بندهای قدرتمند الگوریتم KNN است. در این تحقیق عملکرد KNN را روی دیتاست IRIS مورد بررسی قرار دادیم و برای ارزیابی روش از ۱۰fold cross validation استفاده نمودیم.
شرح مسئله:
هدف از این پروژه بررسی پیاده سازی Knn روی دیتاست iris است. لذا در ابتدا توضیح اندکی در مورد مجموعه داده IRIS ارائه می گردد و سپس طبقه بند مذکور شرح داده می شود.
مجموعه داده IRIS یا دیتاست IRIS :
مجموعه داده های گل iris یا مجموعه اطلاعات آریز فیشر یک مجموعه داده چند متغیره است که توسط متخصص بریتانیا و زیست شناس رونالد فیشر در مقاله ۱۹۳۶ خود استفاده شده است.استفاده از چندین اندازه گیری در مشکلات تاکسیونی به عنوان مثال از تجزیه و تحلیل خطی خطی . گاهی اوقات داده های آیرس اندرسون نامیده می شود ، زیرا ادگار اندرسون داده ها را برای اندازه گیری تغییرات مورفولوژیکی گل های گل آفتاب سه گونه مرتبط جمع آوری کرده است. دو تن از این سه گونه در شبه جزیره گازپسی “همه از همان مرتع و در همان روز جمع شده بودند و در همان زمان توسط همان فرد با همان دستگاه اندازه گیری شد”.
مجموعه داده ها شامل ۵۰ نمونه از هر یک از سه گونه Iris ( Iris setosa ، Iris virginica و Iris versicolor ) می باشد. چهار ویژگی از هر نمونه اندازه گیری شد: طول و عرض قاشق و گلبرگ ، در سانتی متر. بر اساس ترکیبی از این چهار ویژگی، فیشر یک مدل تبعیضی خطی برای تشخیص گونه ها از یکدیگر ایجاد کرد.
الگوریتم KNN :
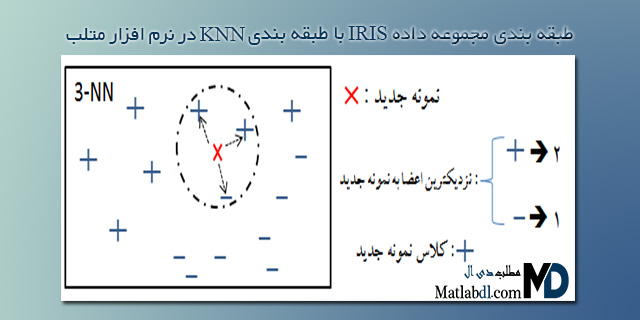
الگوریتم دسته بندی K- نزدیکترین همسایه یک الگوریتم دسته بندی مبتنی بر نمونه ، با ناظر و از دسته الگوریتمهای تنبل میباشد. اساس کار این الگوریتم مقایسه ی میزان شباهت نمونهی جدید با نمونههای موجود در دیتاست اولیه (آموزشی) می باشد. بنابراین جهت بدست آوردن میزان شباهت دو نمونه از معیار فاصله ی دو نمونه استفاده میشود که روش های متفاوتی جهت بدست آوردن فاصله بین دونمونه در فضای جستوجوی مساله وجود دارد که از جملهی آنها میتوان به فاصله اقلیدوسی ، فاصله مینکوفسکی و فاصله منهتن اشاره کرد.
جهت اینکه الگوریتم تشخیص دهد که کلاس نمونه جدید چیست؛ الگوریتم، K نزدیکترین عضو مجموعه آموزشی نسبت به نمونه جدید را انتخاب میکند و کلاسی که دارای بیشترین عضو در این K عضو باشد به نمونه ی جدید تعلق میگیرد لذا الگوریتم مذکور میتواند به صورت زیر خلاصه گردد:
- تعداد همسایه ها (K) را انتخاب کن.
- K نزدیکترین نمونهی موجود در مجموعه داده به نمونه را انتخاب کن.
- کلاس غالب بین این K عضو را انتخاب کرده و به نمونه جدید اختصاص بده.
از مزایا و معایب روش K-نزدیکترین همسایه به موارد زیر اشاره کرد:
مزایا:
- آموزش آن بسیار سریع است.
- یادگیری آن آسان و ساده است.
- در مقابل مجموعه آموزشی نویزدار مقاوم است.
معایب:
- مبتنی بر K است (تعیین K مناسب)
- پیچیدگی محاسباتی بالایی دارد
- محدودیت حافظه دارد
- با توجه به اینکه یک روش مبتنی بر یادگیری بانظارت و الگوریتمی تنبل است، کند میباشد.
نتایج به دست آمده :
جدول زیر نتایج مدل حاصله را روی داده های iris در هر بار تکرار ۱۰-fold نشان می دهد:

میانگین نتایج مذکور برابر است با: ۹۴٫۶۶
این عدد حاصل از میانگین گیری از نتایج جدول بالا است.
همچنین بخوانید: مقایسه کارایی الگوریتم KNN و CART روی مجموعه داده رادار
توجه:
کارشناسان وب سایت MATLABDL قادر به انجام پروژه در زمینه های مشابه نیز می باشند.
قیمت پروژه : ۵۸۰۰۰ تومان
حجم : ۴۴ کیلوبایت
منبع : مطلب دی ال
رمز فایل : www.matlabdl.com
(این پروژه به صورت اختصاصی توسط برنامه نویسان مطلب دی ال تهیه شده است )


دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.